by Philip Pilkington
Article of the Week from Fixing the Economists
Lars Syll has recently published an excellent post on the dilemma of probability theory when applied to the social sciences in general and economics in particular. Syll argues that in order to apply probability theory — which is deeply embedded not simply in mainstream economic models but also in econometric techniques — we must first be sure that the underlying system being studied conforms to certain presuppositions of probability theory.

Syll illustrates this nicely by comparing the economy with a roulette wheel — something that, if ‘fairly balanced’, will actually yield outcomes to which probability theory can be applied.
Probability is a relational element. It always must come with a specification of the model from which it is calculated. And then to be of any empirical scientific value it has to be shown to coincide with (or at least converge to) real data generating processes or structures – something seldom or never done!
And this is the basic problem with economic data. If you have a fair roulette-wheel, you can arguably specify probabilities and probability density distributions. But how do you conceive of the analogous nomological machines for prices, gross domestic product, income distribution etc? Only by a leap of faith. And that does not suffice. You have to come up with some really good arguments if you want to persuade people into believing in the existence of socio-economic structures that generate data with characteristics conceivable as stochastic events portrayed by probabilistic density distributions!
I think that Syll could have buttressed his piece by providing some empirical evidence in this regard. One aspect of probability theory that data must conform to in order to be properly studied using techniques based on probability theory is known as the Central Limit Theorem.
The Central Limit Theorem basically states the conditions needed for a variable to be ‘normally distributed’. What this means is that the variable can be predicted using the well-known ‘bell-curves’ or ‘Gaussian functions’. If a variable is normally distributed we can use standard probabilistic techniques to analyse it. If it is not then we cannot.
So, what about economic variables? Are they normally distributed? Short answer: no, they are not.
The most well-studied of these is, of course, the stock market. After the crash it is often said that financial markets have ‘fat tails’ and that this implies that they are not predictable using probability theory. It means that events that in a normally distributed curve would be almost impossibly rare actually occur with some frequency in these markets. The best illustration of this is to plot the actual stock market against a normally distributed curve to see how far they diverge. Here is such a graph taken from the book Fractal Market Analysis: Applying Chaos Theory to Investment and Economics:
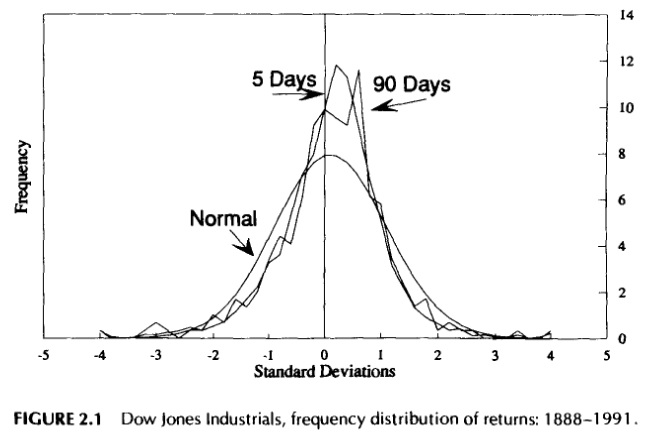
As we can see the actual returns of the Dow Jones diverge substantially from the normal distribution curve. The implications for this, of course, are enormous and I will allow the author of the book to explain them himself.
What does this mean? The risk of a large event’s occurring is much higher than the normal distribution implies. The normal distribution says that the probability of a greater-than-three standard deviation event’s occurring is 0.5%, or 5 in 1,000. Yet the above shows us that the actual probability is 2.4%, or 24 in 1,000. Thus, the probability of a large event is almost five times greater than the normal distribution implies. As we measure still larger events the gap between theory and reality becomes even more pronounced. The probability of a four standard deviation event is actually 1% instead of 0.01%, or 100 times greater. (p26)
But surely this is just the ever-skittish stock market, right? Nope! We find similar properties when studying many economic variables. For example, in a paper entitled Are Output Growth-Rate Distributions Fat-Tailed? Some Evidence from OECD Countries the authors find that GDP growth rates and other economic variables show very similar properties to stock market data. They write,
The foregoing evidence brings strong support to the claim that fat tails are an extremely robust stylized fact characterizing the time series of aggregate output in most industrialized economies… As mentioned, fat tails have been indeed discovered to be the case not only for cross-sections of countries, but also for plants, firms and industries in many countries. In other words, the general hint coming from this stream of literature is in favor of an increasingly “non-Gaussian” economics and econometrics. (p17)
So, what do these authors say in response? Well, the response is usually some vague allusion to some new statistical or mathematical approach. This seems to me to be wholly unfounded. What the authors are actually encountering in the data is not simply a failing of normal distribution curve but instead actual uncertainty or non-ergodicity.
This could probably be shown if different time periods were taken and the probability distributions calculated out. For example, in the Dow Jones data plotted above we could break the data down into, say, five year periods and plot each one. It would quickly become obvious that the curve for, say, 1927-1932 would look vastly different from that of 1955-1960.
What this implies is that events like the 1929 stock market crash are not simply ‘outliers’ that sit neatly off the normal distribution curve. Rather they are properly uncertain events. They cannot be tamed with better models and they cannot be fitted with better statistical equipment. They are simply uncertain — at least when viewed from the point-of-view of a single time-series.
Some, like Taleb, have taken this to mean that predictions are impossible. I entirely disagree with this point-of-view. Many of the uncertain events we see in economics can indeed be predicted. But they can only be predicted by looking at the data within a given historical context or constellation. They cannot be predicted using models or probability estimates or anything of the sort. Rather economists must learn how to read data properly; how to not be sucked in by silly trends; and above all how to appreciate that they are not dealing with material that they can just feed into a computer and expect a neat outcome.




